1 Abstract¶
This document serves to define dataset types and sizes for semi-automated monitoring of scientific performance of the LSST DRP and AP pipelines. It does not cover datasets for testing the full DM system such as data acquisition, data transport, data loading, or the LSST Science Platform.
We start with a summary recommendation for a minimal set of datasets that would be suitable for performance monitoring, regression testing, and estimation of Key Performance Metrics (KPMs) for the LSST DM Science Pipelines. We next define and provide guidelines for the processing workflow and cadence, and monitoring and assessment of test datasets divided into groups. We refer to these groups as CI, SMALL, MEDIUM, and LARGE datasets. We finally present more detailed discussion of the existing and near-future planned datasets for DRP and AP Science Performance monitoring.
We provide some approximate sizes of datasets here, however the singular reference for all sizing is the Data Management Sizing Model, DMTN-135. Table 23 in DMTN-135 provides current values for dataset sizes.
2 Executive Summary¶
DRP Scientific Performance Monitoring can be primarily accomplished through a monthly processing of the HSC RC2 dataset from the SSP survey supplemented by less frequent processing of the much larger HSC PDR2. This needs to be supplemented by HSC observations in crowded fields. The DESC DC2 simulated dataset should also be included in the future.
AP Scientific Performance Monitoring can be accomplished through analysis of the DECam HiTS survey, HSC SSP PRD2-PDR1, plus an additional high-cadence multi-band survey.
Datasets for Continuous Integration (CI)-level tests and regression monitoring can be constructed out of subsets from the full DRP and AP dastasets identified above. Several such datasets currently exist and are being regularly tested through NCSA and Jenkins and are being monitored in SQuaSH.
3 Dataset Types and Goals¶
We identify 4 scales of datasets: CI, SMALL, MEDIUM, and LARGE. These are meant to span a range of computational requirements, response time, and fidelity of performance measurements.
3.1 CI¶
Goals
Test that key initial processing steps execute
Allow checks for reasonable ranges of, for example,
Numbers of stars
Photometric zeropoints
Requirements
Runs less than 15 minutes wall time on 16 cores
Good data that is expected to be successfully processed.
Can be run by developer on an individual machine
Steps
Instrument-Signature Removal
Single-Frame Processing
3.2 SMALL¶
Goals
Fuller integrated testing
Verify that DIA works
Monitor quantities to 25%:
Numbers of stars
zeropoints
KPMs
Numbers of detected DIA sources
Requirements
1 hour on 16-32 cores
Coadd at least 5 detectors
Run image-image DIA
Steps
Instrument-Signature Removal
Single-Frame Processing
Coadd
Difference Image Analysis
Forced Photometry
3.3 MEDIUM¶
Goals
Monitor quantities to 10%, both static sky and DIA
Include known edge cases
Suitable for daily tracking of regression both in metrics and robustness
Generate DRP/DPDD by running SDM Standardization.
Requirements
24 hours on 64-128 cores
At least 2 filters
Coadd at least 5 full focal-plane images per filter
Run image-template DIA
Steps
Instrument-Signature Removal
Single-Frame Processing
Coadd
Multiband detection, merging, and measurement
Difference Image Analysis
Forced Photometry
3.4 LARGE¶
Requirements
168 hours on 512 cores
At least 3 filters
Coadd at least 10 full focal-plane images/filter
Run image-template DIA for 5 epochs of same field
Goals
Peformance Report for static sky and DIA. Monitor numbers to 5%.
KPMs numbers should be suitable to predict full survey performance to ~50%
Generate DRP/DPDD
Allow testing of loading of data into DAX.
Steps
Instrument-Signature Removal
Single-Frame Processing
Coadd
Multiband detection, merging, and measurement
Difference Image Analysis
Forced Photometry
Ingest of DRP data into database/DPDD structure
The SDM Standardization process to generate the DPDD should always be run for at least MEDIUM and LARGE datasets. However, if the process is fast enough, it should be run following the processing of all datasets.
4 DRP Test Datasets¶
The DRP team semi-regularly processes three datasets (all public Subaru Hyper Suprime-Cam data) at different scales: testdata_ci_hsc, HSC RC2, and HSC PDR1.
4.1 CI¶
4.1.1 validation_data_{cfht,decam}¶
There are “validation_data” CI-sized datasets for each of CFHT and DECam (and HSC, see next section). These are
Each of these is part of CI and regularly used for simple execution testing and coarse performance tracking. There is no ISR, coadd, or DIA processing run. These data repositories also contain reference versions of processed data to ease comparison of specific steps without re-processing the full set of data.
4.2 SMALL¶
4.2.1 testdata_ci_hsc¶
The testdata_ci_hsc package (https://github.com/lsst/testdata_ci_hsc) includes just enough data to exercise the main steps of the current pipeline: single-frame processing, coaddition, and coadd processing. The input data comprises 33 CCD images from 12 HSC visits in r and i band, pre-made master darks, dome flats, sky flats, biases and detector defect files for these, and the necessary subset of the PS1-PV3 reference catalog. These data total 8.3 GB. The ci_hsc package is run to process the testdata_ci_hsc data automatically on a nightly basis by the CI system and can be explicitly included in developer-initiated CI runs on development branches. The package also includes some simple tests to make sure that the expected outputs exist, but practically no tests of algorithmic or scientific correctness. Both by name and content, this is a CI-level dataset as defined above.
4.2.2 https://github.com/lsst/validation_data_hsc¶
56 GB raw + master calibrations
The entire validation_data_hsc repo is 250 GB because it includes a set of single-frame- and coadd-processed data
Calibration data available as pre-computed masters and used to do ISR
Currently processed on a daily (8 hour?) cadence through to coadd
Currently not used for DIA.
4.3 MEDIUM¶
4.3.1 HSC RC2¶
The “RC2” dataset consists of two complete HSC SSP-Wide tracts and a single HSC SSP-UltraDeep tract (in the COSMOS field). This dataset is processed every two weeks using the weekly releases of the DM stack. The processing includes the entire current DM pipeline (including jointcal, which is not included in ci_hsc) as well as the pipe_analysis scripts, which generate a large suite of validation plots, and an uplodate of the results of validate_drp to SQuaSH. Processing currently requires some manual supervision, but we expect processing of this scale to eventually be fully automated. See also https://confluence.lsstcorp.org/display/DM/Reprocessing+of+the+HSC+RC2+dataset
The HSC RC2 data is presently (2021-02-02) available at NCSA at in /datasets/hsc/repo. The HSC dataset was defined in a JIRA ticket: Redefine HSC “RC” dataset for bi-weeklies processing
Particular attention was paid in defining this dataset for it to consist of both mostly good data plus some specific known more challenging cases (see above JIRA issue for details). Explicitly increasing the proportion of more challenging cases increases the efficiency of identifying problems for a fixed amount of compute resources at the expense of making the total scientific performance numbers less representative of a the average quality for a full-survey-sized set of data. This is a good tradeoff to make, but also an important point to keep in mind when using the processing results of such datasets to make predictions of performance of the LSST Science Pipelines on LSST data.
The monthly processing of this dataset is tracked at: Reprocessing of the HSC RC2 dataset
The DM Tech Note DMTN-088 provides a brief introduction to the processing of this dataset at the LSST Data Facility (LDF), i.e., NCSA. There are some updates in the un-merged branch DMTN-088 (DM-15546)
The fields are defined in the JIRA issue at https://jira.lsstcorp.org/browse/DM-11345 to be:
Field |
Tract |
Filter |
NumVisits |
VisitList |
|---|---|---|---|---|
WIDE_VVDS |
9697 |
HSC_G |
22 |
6320^34338^34342^34362^ 34366^34382^34384^34400^ 34402^34412^34414^34422^ 34424^34448^34450^34464^ 34468^34478^34480^34482^ 34484^34486 |
WIDE_VVDS |
9697 |
HSC-R |
22 |
7138^34640^34644^34648^ 34652^34664^34670^34672^ 34674^34676^34686^34688^ 34690^34698^34706^34708^ 34712^34714^34734^34758^ 34760^34772 |
WIDE_VVDS |
9697 |
HSC-I |
33 |
35870^35890^35892^35906^ 35936^35950^35974^36114^ 36118^36140^36144^36148^ 36158^36160^36170^36172^ 36180^36182^36190^36192^ 36202^36204^36212^36214^ 36216^36218^36234^36236^ 36238^36240^36258^36260^ 36262 |
WIDE_VVDS |
9697 |
HSC-Z |
33 |
36404^36408^36412^36416^ 36424^36426^36428^36430^ 36432^36434^36438^36442^ 36444^36446^36448^36456^ 36458^36460^36466^36474^ 36476^36480^36488^36490^ 36492^36494^36498^36504^ 36506^36508^38938^38944^ 38950 |
WIDE_VVDS |
9697 |
HSC-Y |
33 |
34874^34942^34944^34946^ 36726^36730^36738^36750^ 36754^36756^36758^36762^ 36768^36772^36774^36776^ 36778^36788^36790^36792^ 36794^36800^36802^36808^ 36810^36812^36818^36820^ 36828^36830^36834^36836^ 36838 |
WIDE_VVDS |
9697 |
TOTAL |
143 |
Size: 1.7 TB |
Field |
Tract |
Filter |
NumVisits |
VisitList |
|---|---|---|---|---|
WIDE_GAMA15H |
9615 |
HSC_G |
17 |
26024^26028^26032^26036^ 26044^26046^26048^26050^ 26058^26060^26062^26070^ 26072^26074^26080^26084^ 26094 |
WIDE_GAMA15H |
9615 |
HSC-R |
17 |
23864^23868^23872^23876^ 23884^23886^23888^23890^ 23898^23900^23902^23910^ 23912^23914^23920^23924^ 28976 |
WIDE_GAMA15H |
9615 |
HSC-I |
26 |
1258^1262^1270^1274^ 1278^1280^1282^1286^ 1288^1290^1294^1300^ 1302^1306^1308^1310^ 1314^1316^1324^1326^ 1330^24494^24504^24522^ 24536^24538 |
WIDE_GAMA15H |
9615 |
HSC-Z |
26 |
23212^23216^23224^23226^ 23228^23232^23234^23242^ 23250^23256^23258^27090^ 27094^27106^27108^27116^ 27118^27120^27126^27128^ 27130^27134^27136^27146^ 27148^27156 |
WIDE_GAMA15H |
9615 |
HSC-Y |
26 |
380^384^388^404^ 408^424^426^436^ 440^442^446^452^ 456^458^462^464^ 468^470^472^474^ 478^27032^27034^27042^ 27066^27068 |
WIDE_GAMA15H |
9615 |
TOTAL |
112 |
Size: 1.4 TB |
Field |
Tract |
Filter |
NumVisits |
VisitList |
|---|---|---|---|---|
UD_COSMOS |
9813 |
HSC_G |
17 |
11690^11692^11694^11696^ 11698^11700^11702^11704^ 11706^11708^11710^11712^ 29324^29326^29336^29340^ 29350 |
UD_COSMOS |
9813 |
HSC-R |
16 |
1202^1204^1206^1208^ 1210^1212^1214^1216^ 1218^1220^23692^23694^ 23704^23706^23716^23718 |
UD_COSMOS |
9813 |
HSC-I |
33 |
1228^1230^1232^1238^ 1240^1242^1244^1246^ 1248^19658^19660^19662^ 19680^19682^19684^19694^ 19696^19698^19708^19710^ 19712^30482^30484^30486^ 30488^30490^30492^30494^ 30496^30498^30500^30502^ 30504 |
UD_COSMOS |
9813 |
HSC-Z |
31 |
1166^1168^1170^1172^ 1174^1176^1178^1180^ 1182^1184^1186^1188^ 1190^1192^1194^17900^ 17902^17904^17906^17908^ 17926^17928^17930^17932^ 17934^17944^17946^17948^ 17950^17952^17962 |
UD_COSMOS |
9813 |
HSC-Y |
52 |
318^322^324^326^ 328^330^332^344^ 346^348^350^352^ 354^356^358^360^ 362^1868^1870^1872^ 1874^1876^1880^1882^ 11718^11720^11722^11724^ 11726^11728^11730^11732^ 11734^11736^11738^11740^ 22602^22604^22606^22608^ 22626^22628^22630^22632^ 22642^22644^22646^22648^ 22658^22660^22662^22664 |
UD_COSMOS |
9813 |
NB0921 |
28 |
23038^23040^23042^23044^ 23046^23048^23050^23052^ 23054^23056^23594^23596^ 23598^23600^23602^23604^ 23606^24298^24300^24302^ 24304^24306^24308^24310^ 25810^25812^25814^25816 |
UD_COSMOS |
9813 |
TOTAL |
177 |
Size: 3.2 TB |
This dataset satisfies the definition above for a MEDIUM dataset.
4.3.2 HSC RC3 (proposed)¶
As survey operations approaches and our ability to process and analyze larger datasets increases, there is a need for a dataset that is more substantial than RC2, allowing us to identify and test the handling of more “edge cases” by the science pipelines. We thus propose the creation of an HSC “RC3” dataset that has the following characteristics:
Covers a contiguous area that spans more than a tract in size
Contains data taken with multiple physical filters that map to the same “effective” filter (e.g., both HSC-I and HSC-I2, which map to “i”)
Is sufficient for creating templates for AP difference imaging in the COSMOS field
Provides a long time baseline sufficient to measure proper motions and parallaxes
Includes data with rotational dithers
Includes “all” HSC visits in the COSMOS field for “full-depth” testing of pipelines
Samples fields at both high and low Galactic latitudes
Proposal:
We will retain all data that are currently part of RC2, which were selected to represent some edge cases. All data proposed below will be in addition to the existing RC2 data. Because the COSMOS field lies within a larger WIDE region of the HSC-SSP, we propose to include all COSMOS data in RC3, plus adjacent tracts from the WIDE footprint that create a contiguous field extending to the “edge” of the survey footprint. (Suggestion: include tracts 9812-9814, 9569-9572, and 9326-9329; see the figure below for a map of HSC tracts.) This enables all of the following:
Full survey depth coadds in the COSMOS field.
COSMOS “truth” table of deep HST galaxy, star, and transient/variable measurements for comparison.
COSMOS provides a long time baseline over which to validate parallax/proper motion algorithms (though the lack of dithering may be an issue; including dithered WIDE data may alleviate this).
COSMOS has data from both HSC-I/HSC-I2 and also HSC-R/HSC-R2. We can thus test processing on, e.g., only HSC-I, only HSC-I2, or the combination of them both.
The large number of visits in COSMOS means we can create independent coadds consisting of separate sets of visits.
Extending over a large area provides a dataset to use in developing QA tools (e.g., survey property maps).
Extends to the edge of the survey footprint to explore issues near survey boundaries.
Can use WIDE data when proper dithering is required, but COSMOS data when depth is more important.
Additional considerations:
COSMOS and the current RC2 dataset provide little variation in declination or Galactic latitude. We may need to include some Subaru+HSC PI data to get higher source densities.
We could consider cherry-picking some region(s) of the sky with, e.g., a known rich galaxy cluster (e.g., RC2’s tract 9615 was selected for this reason + a big galaxy), Galactic cirrus, a nearby globular cluster or dwarf galaxy, or other features to enable exercising/testing specific algorithms and capabilities.
It is vital to inject synthetic sources into data for validation purposes. However, the details of what types of sources to inject, how many tracts to inject them into, and others can be decided after the RC3 dataset has been created.
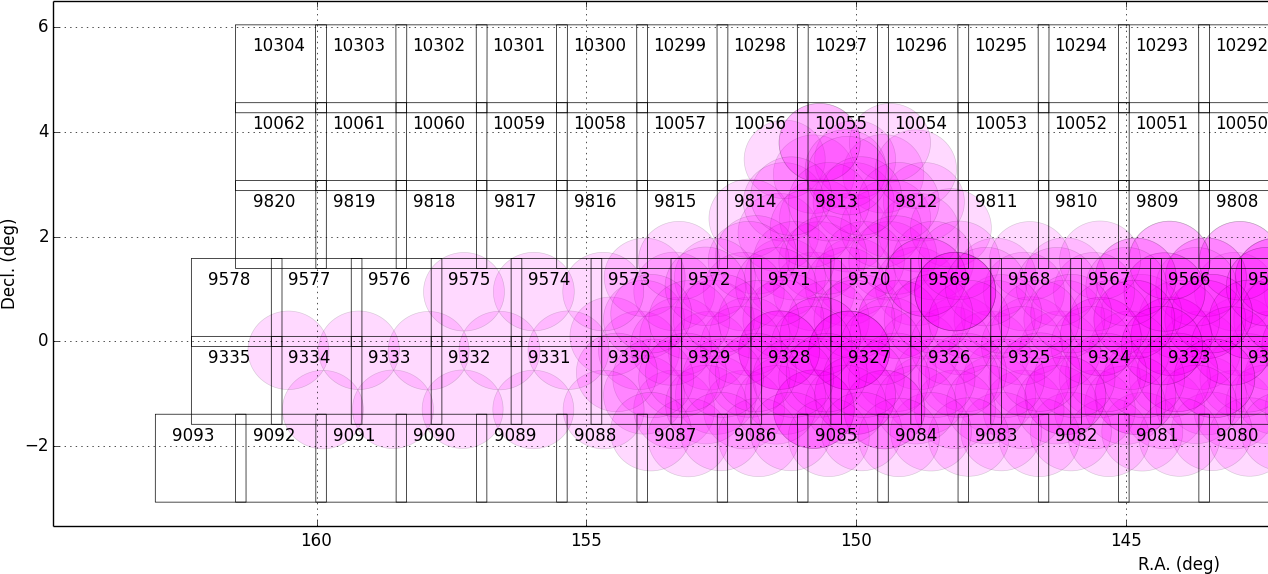
Figure 1 Map of the HSC-SSP tracts in the region near the COSMOS field (centered on tract 9813). The proposed RC3 dataset would contain tracts 9812-9814, 9569-9572, and 9326-9329, including all data from the DEEP/ULTRADEEP layers in the COSMOS field.¶
This section is a condensed encapsulation of discussion that took place on this Confluence page; for more details about the considerations that were discussed, please consult that page.
4.4 LARGE¶
4.4.1 HSC SSP PDR1 and PDR2¶
The full HSC SSP Public Data Release 1 (PDR1) dataset has been processed by LSST DM twice. This is a LARGE dataset. The timescale for these runs is essentially as-needed. The processing of these large dataset could be increased as the workflow and orchestration tooling for automated execution improves. We expect this scale of processing to always require some manual supervision (but significantly less than it does today). As more data becomes available with future SSP public releases, we expect this dataset to grow to include them.
See reports at:
The HSC Public Data Release 2 (PDR2) dataset was released by HSC in the Summer of 2019. This dataset is being copied to NCSA and will be available at /datasets/hsc/raw/ssp_pdr2. PDR2
Contains 5654 visits in 7 bands (grizy plus two narrow-band filters)
Covers 119 tracts
Data from 3 survey tiers: WIDE, DEEP, UDEEP
Is 13 times larger than RC2
Takes 80,000 core hours. 80% of this is spent in the full multiband processing
It is appropriate for DRP and for AP testing and performance monitoring. As with PDR1, PDR2 is similarly a LARGE dataset.
4.5 DESIRED DATASETS¶
In the future, there are at least two additional dataset needs:
4.5.1 Less Large LARGE¶
Some important features of data are sufficiently rare that it’s hard to include all of them simultaneously in just the three tracts of the RC dataset. A dataset between the RC and PDR1/2 scales, run perhaps on monthly timescales (especially if RC processing can be done weekly as automation improves), would be useful to ensure coverage of those features. 10-15 tracts is probably the right scale.
4.5.2 Missing Features¶
Three important data features are missed in all of the datasets described above, as they are generically missing all datasets that are subsets of HSC SSP PDR1/2 and RC2:
Differential chromatic refraction (HSC has an atmospheric dispersion corrector)
LSST-like wavefront sensors (HSC’s are too close to focus to be useful for learning much about the state of the optical system)
Crowded stellar fields
A (not yet identified) DECam dataset could potentially address all of these issues, but characterizing the properties of DECam at the level already done for HSC may be difficult, and would probably be necessary to fully test the DM algorithms for which DCR and wavefront sensors are relevant (e.g., physically-motivated PSF modeling). Many non-PDR1/2+RC2 HSC datasets do include more interesting variability or crowded fields, so it might be most efficient to just add one of these to our test data suite, and defer some testing of DCR or wavefront-sensor algorithms until data from ComCam or even the full LSST camera are available.
4.6 DRP Summary¶
CI, SMALL, MEDIUM, and LARGE datasets exist suitable for significant amount of Science Pipelines performance monitoring. The addition of a dataset on a crowded field would help exercise a key portion of the Science Pipelines that currently is uncertain. Technical investigations of (1) using wavefront-sensor data and (2) a system without an ADC may wait until commissioning data is available from ComCam or the full LSSTCam.
5 AP Test Datasets¶
Summary recommendations:
Use a subset of HiTS for quick turnaround processing, smoke tests, etc. DONE.
Use the DECam Bulge survey for crowded field tests. IN PROGRESS.
Select a subset of HSC SSP PDR1 vs PDR2. TICKET OPEN.
Use a DES Deep SN field for large-scale processing.
Desiderata for AP testing:
Tens of epochs per filter per tract in order to construct templates for image differencing and to characterize variability
The ability to exercise as many aspects of LSST pipelines and data products as possible
Public availability (so that we can feely recruit various LSST stakeholders)
Potential for enabling journal publications (both technical and scientific) so that various stakeholders beyond LSST DM may have direct interest in contributing tools and analysis
Datasets from at least two different cameras, so that we can isolate effects of LSST pipeline performance from camera-specific details (e.g., ISR, PSF variations) that impact the false-positive rate
At least one dataset should be from HSC, to take advantage of Princeton’s work on DRP processing
At least one dataset should be in multiple filters from a camera without an ADC to test DCR
Probably only two cameras should be used for regular detailed processing, to avoid spending undue DM time characterizing non-LSST cameras. HSC and DECam are the clear choices for this
Datasets should include regions of both high and low stellar densities, to understand the impact of crowding on image differencing
Ideally, data will be taken over multiple seasons to enable clear separation of templates from the science images
Datasets sampling a range of timescales (hours, days, … years) provide the most complete look at the real transient and variable population
Substantial dithering or field overlaps will allow us to test our ability to piece together templates from multiple images (some transient surveys, such as HiTS, PTF, and ZTF, use a strict field grid)
There is a balance to be struck between using datasets that have been extensively mined scientifically by the survey teams as opposed to datasets that have not been exploited completely. If published catalogs of variables, transients, and/or asteroids exist, they will aid in false-positive discrimination and speed QA work. On the other hand, well-mined datasets may be less motivating to work on, particularly for those outside LSST DM.
LSST-like cadences to test Solar System Orbit algorithms
5.1 CI¶
5.1.1 DECam HiTS¶
A subset of data intended for CI AP testing (with Blind15A_40 and Blind15A_42) is in https://github.com/lsst/ap_verify_ci_hits2015
This subset is only 3 visits and 2 CCDs per visit.
5.2 SMALL¶
5.2.1 DECam HiTS¶
Available on lsst-dev in /datasets/decam/_internal/raw/hits
Total of 2269 visits available
up to 14 DECam fields taken over two seasons, and a larger number (40-50) of fields observed only during a single season ; 4-5 epochs per night in one band (g) over a week
Essentially only g-band, as there are only a few r-band visits available. This would not then actually satisfy the 2-band MEDIUM color requirement outlined above.
Blind15A_26, Blind15A_40, and Blind15A_42 have been selected for AP testing in https://github.com/lsst/ap_verify_hits2015
5.3 MEDIUM¶
5.3.1 HSC SSP PDR1+PDR2¶
Planned work to build templates from PDR1 and then run subtractions from the new data in PDR2 from later years.
It’s less clear that it’s feasible to do active regular testing of DIA on LARGE datasets. MEDIUM should be sufficient to characterize the key science performance goals.
5.4 AP Candidate Additional Datasets¶
5.4.1 DECam DES SN fields¶
8 shallow SN fields, 2 deep SN fields
griz observation sequences obtained ~ weekly
Deep fields have multiple exposures in one field in the same filter each night, with other filters other nights; shallow fields have a single griz sequence in one night. Former is more LSST-like.
Raw data are public
10 fields from 2014 (DES Y2) in field SN-X3.
g (no particular reason for this choice)
Visits = [371412, 371413, 376667, 376668, 379288, 379289, 379290, 381528, 381529]
Available on lsst-dev in /datasets/des_sn/repo_Y2
5.4.2 HSC New Horizons¶
Crowded stellar field (Galactic Bulge)
Available to us (not fully public?); unclear details of numbers of epochs, etc.
Scientifically untapped
Available on lsst-dev at /datasets/hsc/raw/newhorizons/
5.4.3 DECam Bulge survey¶
Crowded stellar field
Propoasal ID 2013A-0719 (PI Saha)
Limited publications to date: 2017AJ….154…85V; total boundaries of survey unclear.
Published example shows that globular cluster M5 field has 50+ observations over 2+ seasons in each of ugriz
5.4.4 DECam NEO survey¶
PI L. Allen
320 square degrees; 5 epochs a night in a single filter with 5 minute cadence, repeating for three nights
3 seasons of data
5.4.5 HSC SSP Deep or Ultra-Deep¶
grizy; exposure times 3-5 minutes; tens of epochs available
Two UD fields and 15 deep fields
Open Time observations from Yoshida
Tens of epochs over a couple of nights for a range of fields
GAMA09 and VVDS overlap SSP wide (only) but Yoshida reports the seeing was bad (~1”)
5.4.6 Deep DECam Outer Solar System Survey (DDOSSS)¶
P.I. D. Trilling.
13 total nights across 2019A, B semesters.
VR=27 mag. Observations are in several bands.
Goal is 5,000 KBOs.
Provides a deep dataset and a good source of comparison for deep Solar System object recovery, which is a key interesting science case.
6 Datasets considered but not selected¶
CFHT-SNLS
Suitable for some AP performance. But no obvious reason to select CFHT over DECam.
CFHTLS-Deep
Suitable, but no obvious reason to select CFHT over DECam
PTF
Tens to thousands of epochs of public images available in two filters (g & R), but camera characteristics are markedly different–2”+ seeing, 1” pixels, and much shallower.
ZTF
Same sampling issues as PTF. obs_ztf exists, but has not been thoroughly tested. Not all desired calibration products are presently (2019-10-07) publicly available.
DLS
MOSAIC data. Was processed through the DM Science Pipelines once (https://dmtn-063.lsst.io/), but there is no supported LSST Science Pipelines module for the camera, so there is no possibility of ongoing analysis.
7 Timescale for preserving processed datasets¶
Preserved outputs are very useful for people testing downstream components without needing to regenerate them as needed. With regular reprocessing of datasets, the volume of data on disk will grow rapidly. It is neither necessary nor feasible to preserve all processed datasets in perpetuity. The following gives the required timescales for retaining processed test datasets:
LARGE: A minimum of two datasets should always be preserved as well as two sets of corresponding master calibraions to be used for subsequent processing campaigns. The reason is to be able to compare the results of each subsequent processing campaign. One of the two may be deleted prior to processing the next one if space is needed.
MEDIUM: A minimum of 12 months.
SMALL: 1 month at the most. Datasets in this category should be managed so that there is always at least one available and so that the likelihood of a dataset being deleted while in use is mitigated. The output from each successive run in this category should be preserved at least until 72 hours after the output of the next run is available.
CI: There is no need to preserve any CI datasets.
9 Practical Notes¶
9.1 Calibration¶
Master calibration images will be required prior to processing. We will not be testing the generation of these master calibration images as part of the processing of these datasets for CI, SMALL, and MEDIUM datasets. Such generation is suitable for processing with LARGE datasets, but full testing of calibration should be the subject of a separate effort and planning and additional supporting documentation.
Astrometric and photometric reference catalogs will be required for each dataset.
9.2 Jenkins vs. NCSA¶
The above goals and dataset definitions are written with the NCSA Verification Cluster in mind. The current Jenkins AWS solution has a much smaller number of available cores than the NCSA Verification Cluster. These limitations mean that the CI and SMALL datasets are suited to Jenkins. It would be _possible_ to do occasional MEDIUM runs through Jenkins, but it’s likely more efficient to run them at NCSA.
The CI scale of data should also be possible for a developer to manually run on an individual machine, whether that’s at their desktop or NCSA.
October, 2019: Jenkins is now running at the LDF in the same configuration of a Kubernetes cluster at the LDF. Those pods created could have access to the shared datasystem on the LDF.
10 Future Work¶
Specify as-realized datasets on disk based on these recommendations.